David Vismans, Chief Technology Officer at Hyves (@dvismans)
Everybody has a great internet idea; most people actually think it is so good that they have to keep it to themselves. And then, when they see someone else has built a successful company on top of that idea they think "see, that could have been me".
The thing is, it could very likely not have been you.
Why?
There is something weird about great ideas, when you have one, you think you are half way there. The rest is a matter of just doing it.
Illustrative to this point is that in todays fast moving internet technology industry everybody wants to do a startup; everywhere we see these hip startup weekends drawing large groups of people who cannot resist the dog-whistle that is The Startup. The idea is there! Now let’s do a startup to make it happen!
I am of the opinion that the idea is worth very little, and that is the reason that many startups fail or even never get of the ground. The only thing that matters in getting an idea of the ground is execution.
And that's why it's so hard to get a good a idea to life – execution is very hard.
Luckily the list of things you need for successful execution of pretty much any internet type idea is enumerable. Based on the experience I have at two major Dutch product development companies (Hyves and TomTom) I have created this list.
But first, what makes a good idea fundamentally in my opinion:
Entropy
What?
The value of internet type products is in the new information they create. The idea here is that value comes from new information, and there is a (latent) need for this information.
We see many examples where there is no new information created: someone combines a couple of APIs and mashes up a website that allows you to see for instance "where the girls at". In this example they use the Foursquare API to locate where users that have their sex set to female are together in groups. This is of course funny, but there is no significant new information created - in information theory terms you can say that this product is very compressible. Which usually means that there is someone out there that can build this idea faster than you, because it's not hard.
And that's a thing to remember, if something is hard, you are probably doing something right, you are creating entropy, new information, that has value for someone out there, and will be hard to copy giving you an inherent edge.
Now given that your idea has the potential to create value, what do you need for execution on this great idea?
1. Team
The team creates the product, they
are the product and they will therefore directly determine the success of the product.
The team will transform an
abstract vague idea into
perfect information (machine executable code) and along the way make thousands of small decisions that affect the final shape of the product, they need to be able to make those decisions.
There is no trick here, you cannot get away with people who do not believe in the idea - they will make the wrong decisions - or who people who are not good enough at what they do - they will make the right decisions, but implement them wrong.
Hire only those that meet these requirements, and
do not hire those that you have even the slightest doubt about. Think of it like this: every time you hire someone who does not match the above criteria, someone is secretly replacing parts of the engine of your brand new car with used parts. Your car will still run initially, but it’s quality is inherently being degraded and it will come to a stop in a much shorter time than you expect, and worse,
you will not know when to expect it.
For developing an internet type product, if you are lucky you can do it alone, you have to then unite two disciplines: the discipline of Product Management and the discipline of Software and System Engineering. If you can't do that yourself you will need others. And if you want to be fast in bringing your product to the market you will need to scale your execution, so you will need more people than just you.
2. Iterative Product Development
Creating something new requires strong discipline in forcing yourself to be critical, and not sometimes, but all the time. And the team needs to have this approach too. You need to very regularly play the devil's advocate on your own product and be ruthless on it's qualities and value it creates. The problem here is however that you are in love with it, and if all is well so is the team. Therefore you need to expose your product to people who are in love with other things, and not your product. They will be truly critical.
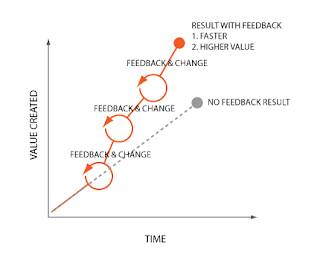
You need to build this feedback loop in from the start, from the idea phase, all the way through to the future versions of the product. There are well know mechanisms to ensure this happens, most of them captured under the over-hyped term "agile product development". This category of methods builds the feedback loop in. It forces you to, as soon as you can, release a minimal shippable product - to get feedback, make changes, and as such evolve your product based on actual feedback. It will make you fail fast as well, but that is what you want, not to waste time.
Everybody in the team needs to understand this philosophy down to its fundamentals, if they do you will have very little waste in you team, meaning that you are not going to be building stuff that has no value.
3. Bootstrapping
If you got the two former points covered, you may now have an idea that creates value, a great team, and a process for iterating to the nearest optimal first version of your product with minimal waste.
Now comes the problem of bootstrapping. How do you get people to use your product - even if it has been brilliantly implemented it is still not creating any value if no one is using it.
Bootstrapping is the process of getting sufficient momentum on the use of your product so that it delivers the value anticipated and you can evolve it further. And this is costly stuff, in most cases it requires you to invest in getting eyeballs on your product, and combined with the viral mechanisms that are available nowadays your product may get traction, but this can be extremely costly. You need to figure out how you are going to bootstrap and gain sufficient momentum well before you start implementation, it may turn out that you cannot afford it. Its then like building a great car in a building with no garage door.
--
That's it, only three things you need, but you may now appreciate why it is so hard to realize that idea you have, and why execution is key.
Getting a good team together is very hard, the market for Product Managers and Engineers is very tight and if they are good these people can work anywhere.
In addition most people have a very traditional waterfall like idea of product development in their genes. The iterative approach is relatively young and only since a couple of years people are starting to truly understand it. Getting people to work in this pattern is very hard if they do not understand the fundamentals behind it, and have never experienced the benefits.
Bootstrapping can be very expensive, and will require a lot of effort if you have no platform that already attracts a lot of traffic.
What about Hyves?
Careful: shameless plug follows!
There are few companies in the Netherlands who get this all right - considering that I feel Hyves is for anyone who is interested in online product development an extremely interesting environment. We've got all three points covered.
Hyves has one of the best engineering teams in the Netherlands, meaning that for anyone who is interested in working in the Product Management discipline the first item on the shopping list can be checked right away.
Hyves more or less adopted Scrum as an iterative product development method two years ago, and since a couple of months we are busy evolving the implementation of this method to the next level. We are not there yet, but with respect to releasing early and often we are there, this is engrained in the minds of the whole team. We release products as often as on a weekly basis, and make changes based on user and focus group feedback.
With millions of users Hyves has got the bootstrapping part covered as well, like very few others we can expose new product to a mass of users, and create value for them in a very short time.
Hyves has the ambition to grow into the best online product development company in the Netherlands. We are constantly building and evolving the team and methods we use. And note that the products we will be developing will not be limited only to the Hyves network, or even to the Netherlands. If this environment and way of working appeals to you, and you are an Engineer or a Product Manager, do not hesitate to contact me.
Emerson: "In every work of genius we recognize our own rejected thoughts, they come back to us with a certain alienated majesty."




